|
|
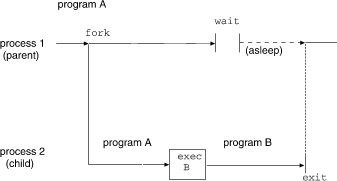
If a process wishes to regain control after execing a second program, it should fork a child process, have the child exec the second program, and the parent wait for the child. This is analogous to a ``call'' except that the fork system call creates a new process that is an exact copy of the calling process. The following figure depicts what is involved in executing a program with a typical fork as the first step:
Process primitives
Because the exec functions simply overlay the new program on the old one, to save the old one requires that it first be split into two copies; one of these can be overlaid, while the other waits for the new overlaying program to finish.
The system call fork does the splitting as in the following call:
proc_id = fork();The newly created process, known as the ``child process'', is a copy of the image of the original process, called the ``parent process''. The system call fork splits the program into two copies, both of which continue to run, and which differ only in the value returned in proc_id. In the child process, proc_id equals zero; in the parent process, proc_id equals a non-zero value that is the process number of the child process. Thus, the basic way to call, and return from, another program is:
if (fork() == 0) /* in child */
execl("/bin/sh", "sh", "-c", cmd, NULL);
And in fact, except for handling errors, this is sufficient.
The fork is zero, so it calls execl which does the cmd and then dies.
In the parent, fork returns non-zero so it skips the execl.
(If there is any error, fork returns -1).
A child inherits its parent's permissions, working-directory, root-directory, open files, etc. This mechanism permits processes to share common input streams in various ways. Files that were open before the fork are shared after the fork. The processes are informed through the return value of fork as to which is the parent and which is the child. In any case the child and parent differ in three important ways:
The fork system call creates a child process with code and data copied from the parent process that created the child process. Once the copying is completed, the new (child) process is placed on the runnable queue to be scheduled. Each child process executes independently of its parent process, although the parent may explicitly wait for the termination of that child or any of its children. Usually the parent waits for the death of its child at some point, since this wait call is used to free the process-table entry used by the child. See the discussion in ``Process termination'' for more detail.
Calling fork creates a new process that is an exact copy of the calling process. The one major difference between the two processes is that the child gets its own unique process ID. When the fork process has completed successfully, it returns a 0 to the child process and the child's process ID to the parent. If the idea of having two identical processes seems a little funny, consider this:
#include <errno.h>pid_t ch_pid; int ch_stat, status; char *p_arg1, *p_arg2; void exit();
if ((ch_pid = fork()) < 0) {
/* Could not fork... check errno */
} else if (ch_pid == 0) { /* child */ (void)execl("/usr/bin/prog2", "prog", p_arg1, p_arg2, (char *)NULL); exit(2); /* execl() failed */ } else { /* parent */ while ((status = wait(&ch_stat)) != ch_pid) { if (status < 0 && errno == ECHILD) break; errno = 0; } }
Example of fork
Because the new exec'd process takes over the child process ID, the parent knows the ID. What this boils down to is a way of leaving one program to run another, returning to the point in the first program where processing left off.
Keep in mind that the fragment of code above includes minimal checking for error conditions, and has potential for confusion about open files and which program is writing to a file. Leaving out the possibility of named files, the new process created by the fork or exec has the three standard files that are automatically opened: stdin, stdout, and stderr. If the parent has buffered output that should appear before output from the child, the buffers must be flushed before the fork. Also, if the parent and the child processes both read input from a stream, whatever is read by one process will be lost to the other. That is, once something has been delivered from the input buffer to a process the pointer has moved on.
Process creation is essential to the basic operation of UNIX System V because each command run by the Shell executes in its own process. In fact, execution of a Shell command or Shell procedure involves both a fork and an overlay. This scheme makes a number services easy to provide. I/O redirection, for example, is basically a simple operation; it is performed entirely in the child process that executes the command, and thus no memory in the Shell parent process is required to rescind the change in standard input and output. Background processes likewise require no new mechanism; the Shell merely refrains from waiting for commands executing in the background to complete. Finally, recursive use of the Shell to interpret a sequence of commands stored in a file is in no way a special operation.